一致性哈希
首先,当我们使用redis集群时,会有多个服务器来保存数据,我们将数据保存在哪个服务器是根据hash算法来实现的,比如有一个数据data和四台redis服务器,那么这个数据保存的位置=hash(data) % 4 = 2,就是保存在第二个服务器中。
但是这种方式有一个问题,那就是当我们增加或者减少一台服务器时,通过hash算法算出来的服务器位置就出现了偏差,比如原先是4台服务器,算出的结果是2,说明data保存在第二台服务器中,之后再去服务器中去data时,由于服务器数量减少了一个台,那么hash(data) % 3 = 1,得出的结果是data保存在第一台服务器中,这明显是不对的,这样的话所有redis中的数据都需要重构才行,这是一个严重的问题。
为了解决上述问题,出现了一致性哈希算法,这个算法也是通过取模的方法。原先的hash算法是用过服务器的数量来取模,而一直性hash算法则是通过2^32来取模。直白的说,就是将hash空间想象成一个圆环,范围为0-2^32-1
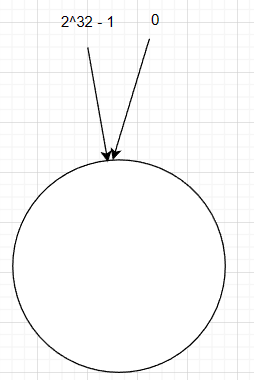
这个圆环是顺时针增加的,这个圆环我们称之为hash环
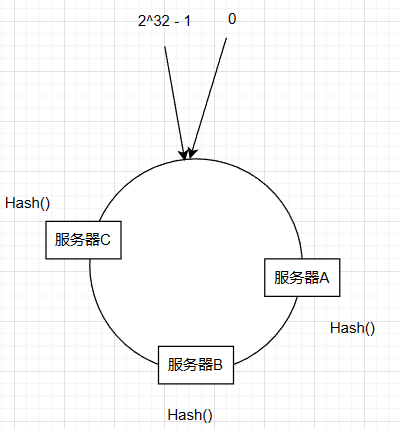
首先我们对服务器进行hash值计算,可以对ip或主机名作为关键字进行hash,得到服务器在hash环中的位置
然后对于需要存储的数据,我们再进行hash计算,得到数据在hash环中的位置
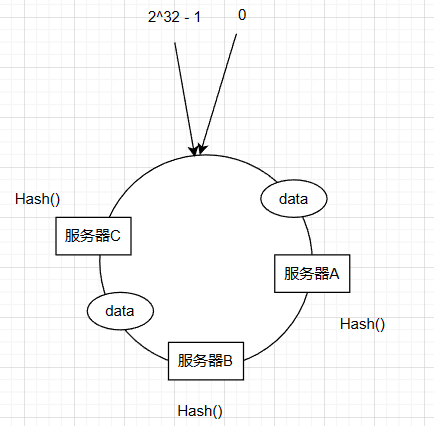
然后在数据对应环中的位置顺时针走,遇到的第一个服务器就作为保存该数据的服务器,
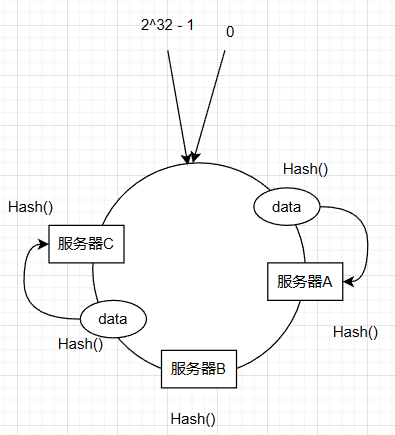
当其中一个服务器宕机或者删除了其中一个服务器或者增加了一个服务器,被影响的数据只是被定位到那台服务器中的数据,其他服务器中的数据位置还是正确的
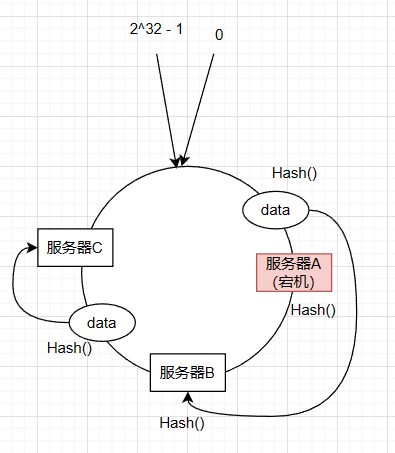
增加服务器也同理
但是一致性hash算法也有问题,那就是数据倾斜的问题,当服务器的节点太少,会导致服务器在hash环中分布不均匀,从而导致大多数数据集中在一台服务器中
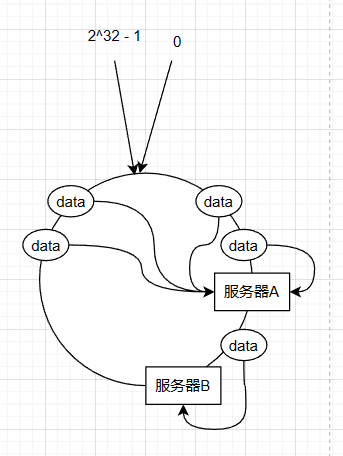
可以看到上图的数据都集中在了服务器A中。
为了解决这个问题,一致性hash算法映入了虚拟节点的机制,即对服务器进行多次hash,每个计算出的hash值都放置该服务器,这个可以通过在服务器ip或主机名后加编号实现
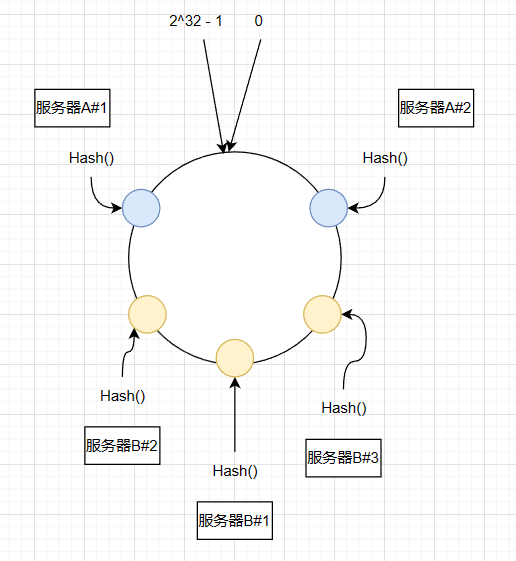
这样定位到服务器B#1、服务器B#2和服务器B#3的数据都放在服务器B中,这样就解决了数据倾斜的问题,在实际中,通常将虚拟节点的数量设置为32甚至更多,这样即使很少的服务节点也能做到相对均匀的数据分布。
OK,over!